Deep-Modal: Real-Time Impact Sound Synthesis for Arbitrary Shapes
ACMMM2020
1Peking University
2University of Maryland
Abstract
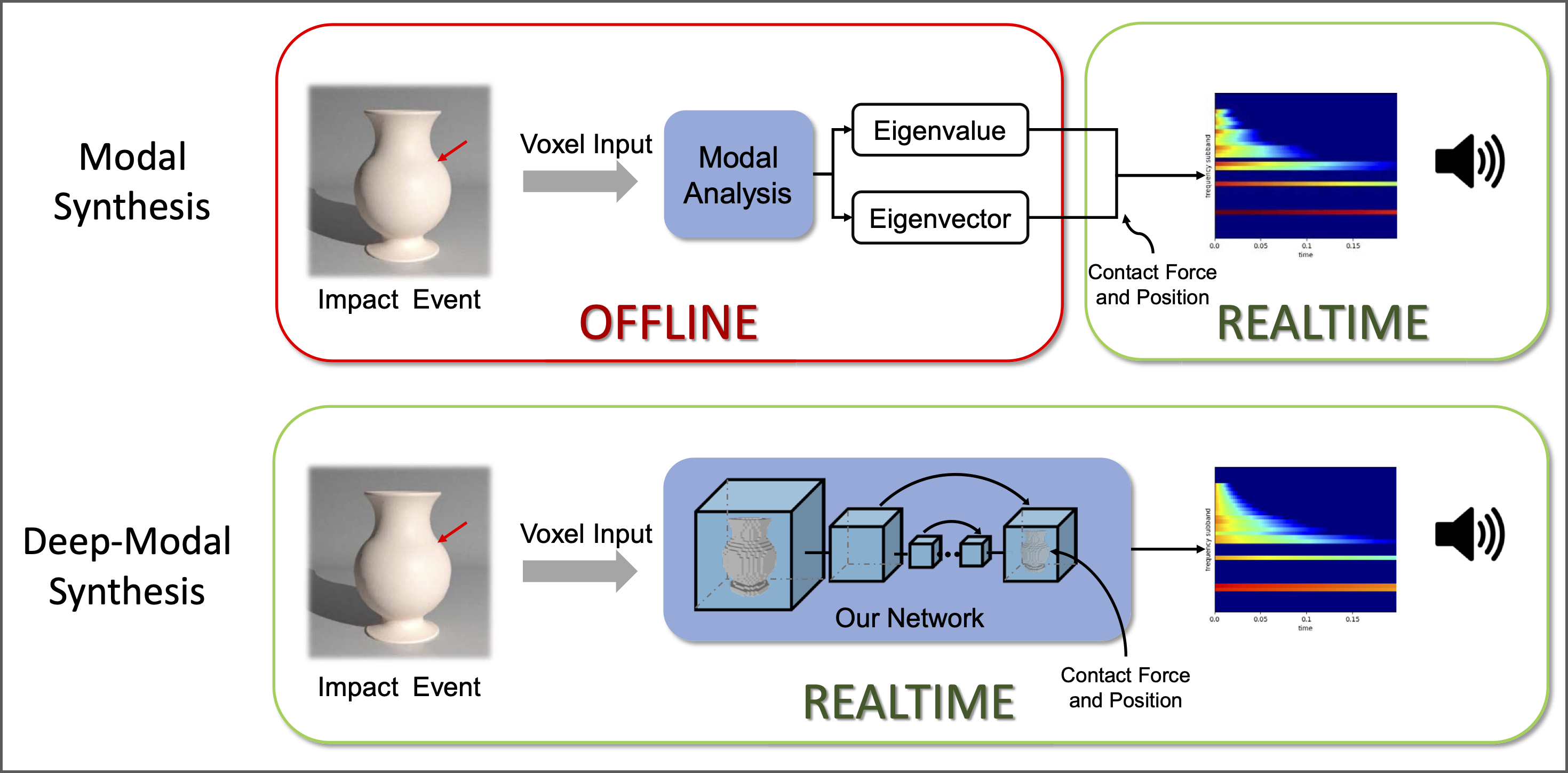
Model sound synthesis is a physically-based sound synthesis method used to generate audio content in games and virtual worlds. We present a novel learning-based impact sound synthesis algorithm called Deep-Modal. Our approach can handle sound synthesis for common arbitrary objects, especially dynamic generated objects, in real-time. We present a new compact strategy to represent the mode data, corresponding to frequency and amplitude, as fixed-length vectors. This is combined with a new network architecture that can convert shape features of 3D objects into mode data. Our network is based on an encoder-decoder architecture with the contact positions of objects and external forces embedded. Our method can synthesize interactive sounds related to objects of various shapes at any contact position, as well as objects of different materials and sizes. The synthesis process only takes ~0.01s on a GTX 1080 Ti GPU. We show the effectiveness of Deep-Modal through extensive evaluation using different metrics, including recall and precision of prediction, sound spectrogram, and a user study.
Bibtex
@inproceedings{jin2020deep,
title={Deep-modal: real-time impact sound synthesis for arbitrary shapes},
author={Jin, Xutong and Li, Sheng and Qu, Tianshu and Manocha, Dinesh and Wang, Guoping},
booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
pages={1171--1179},
year={2020}
}